SynRXN#
SynRXN: curated reaction benchmarks for reproducible reaction informatics
SynRXN organizes atom mapping, reaction classification, property prediction, reaction rebalancing, and synthesis datasets into a versioned, citable benchmark resource with a lightweight Python API.
Why SynRXN?#
Benchmarking reaction-informatics methods is difficult when datasets, splits, reaction representations, and provenance metadata are scattered across releases or publications. SynRXN solves this by providing a consistent data layout, version-aware access, documented schema conventions, and reproducible splitting utilities.
Framework overview#
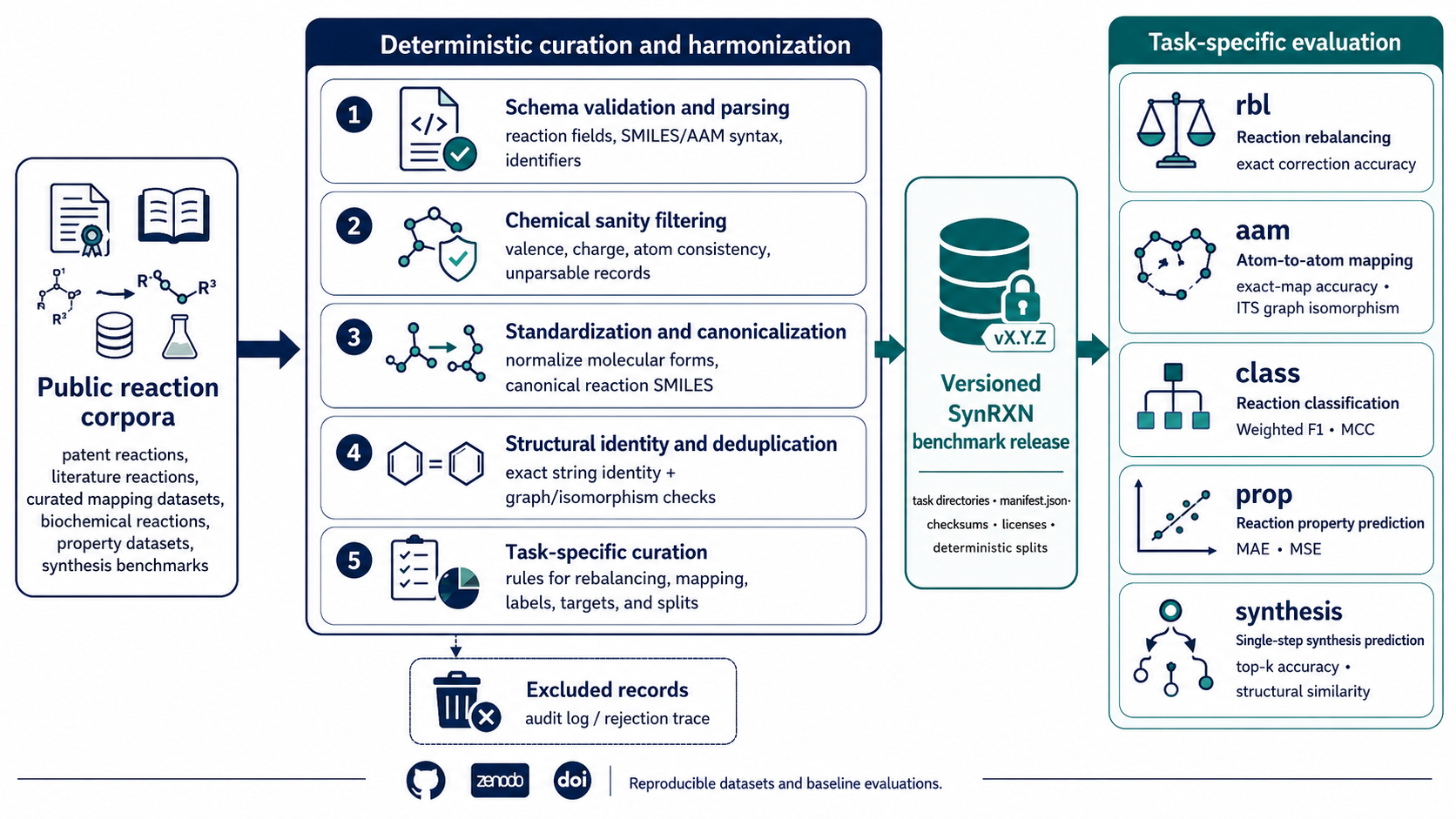
Figure 1. Curated reaction datasets are grouped by benchmark task, distributed through reproducible releases, loaded through a shared API, and evaluated with task-specific workflows.#
The SynRXN pipeline separates the data lifecycle into four practical layers:
Curated assets under
Data/<task>/<dataset>.csv.gz.Versioned distribution through Zenodo records, GitHub releases, or exact Git commits.
Reusable utilities for loading, caching, manifest handling, and splitting.
Task-specific evaluation for mapping, classification, property, rebalancing, and synthesis workflows.
Benchmark collections#
Recover chemically balanced reactions when reactants, products, solvents, catalysts, or auxiliary species are missing.
AAM Atom-to-atom mappingEvaluate predicted atom correspondences against curated, rule-based, or consensus reference mappings.
CLS Reaction classificationAssign reaction classes, named-reaction labels, template identifiers, or hierarchical enzyme annotations.
PROP Property predictionModel kinetic, thermodynamic, and experimental reaction properties such as barriers, enthalpies, rates, yields, and free energies.
SYN Synthesis predictionSupport forward synthesis, retrosynthesis, reagent prediction, condition recommendation, and reaction-center identification.
MECH Mechanism predictionTODO: add datasets for elementary steps, intermediates, and mechanistic pathways.
Quick example#
Install SynRXN, load a released classification benchmark, and inspect the first records:
pip install synrxn
from pathlib import Path
from synrxn.data import DataLoader
loader = DataLoader(
task="classification",
source="zenodo",
version="1.0.0",
cache_dir=Path("~/.cache/synrxn").expanduser(),
)
print(loader.available_names())
df = loader.load("schneider_b")
print(df.head())
Citation#
If you use SynRXN in published work, cite the primary data descriptor and the exact Zenodo version used for your data archive.
@article{phan2026synrxn,
title = {SynRXN: An Open Benchmark and Curated Dataset for Computational Reaction Modeling},
author = {Phan, Tieu-Long and Nguyen Song, Nhu-Ngoc and Stadler, Peter F.},
journal = {Scientific Data},
volume = {13},
pages = {625},
year = {2026},
doi = {10.1038/s41597-026-07260-w},
url = {https://www.nature.com/articles/s41597-026-07260-w}
}